STM32实现动态加载APP
原因
最近看到好多嵌入式操作系统都具有动态加载的相关功能,如Threadx和RT-Thread的moudle功能,但这些功能都与自身系统耦合很严重,大部分都要依赖于自己的工具链。考虑到MDK5使用的人最多,因此决定采用MDK5的相关工具链实现一个方便移植的动态加载实现。本程序中elf文件解析部分参照了RT-Thread的Moudle实现。实现过程中查阅了很多的资料,中间也遇到了蛮多的问题,索性最后都解决了。非常感谢硬汉大哥的文档教程,在里面学到了很多东西,本帖也算是我对论坛的一点点回馈,希望能帮助到有需要的人,相关代码与工程我都会放到附件中,供大家参考。
什么是动态加载?
按照程序的加载方式进行分类,可以分为静态加载和动态加载。静态加载是指所以程序代码都在编译期予以确定,所有程序都需要存储在ROM中,程序尺寸受限于flash的尺寸,运行速度较快,无需预加载。动态加载是在编译期间,依靠函数或者其他手段,从其他的存储介质中将程序加载ram中运行,与静态加载相比更加灵活,可以很方便的进行程序升级,可以把暂时不需要使用的库释放掉,在需要使用的时候在将其加载到内存中,程序尺寸可以做的很大,可以很方便的实现APP程序。
程序功能介绍
本程序实现的是在STM32中实现程序的动态加载,使用起来与windows的dll类似。程序使用dl_load_lib加载相应的库文件到句柄中,加载成功后可使用dl_get_func,通过函数名获得相应函数指针,在不需要使用时可使用dl_destroy_lib对句柄进行释放。
程序使用平台介绍
本程序使用软件平台位MDK5的V6编译器,语法标准采用C99,移植了FATFS作为文件系统,使用楼主自己编写的内存管理函数进行动态内存的管理,硬件平台位STM32H743。
内存管理算法
论坛首发,内存管理算法,支持malloc,realloc,align_alloc,配有内存碎片合并算法(v1.2)
(出处: 硬汉嵌入式论坛)
本次算法进行了部分更新,主要添加内存池式的初始化与分配方法,与硬汉哥在H7教程中的内存管理方法使用方式完全一致,另外代码是根据C99标准编写的,因此编译时需要勾选C99选项。
mem_manage.h
1 | /******************************************************************************** |
mem_manage.h
1 | /******************************************************************************** |
文档说明:内存管理设计文档.pdf
实现原理简介
实现STM32动态加载的问题主要有以下几个:
问题1:被动态加载的APP程序中,程序的基地址是伴随着动态内存变化的,这样就会产生重定位问题,APP中定义数据的地址也会随着程序基地址的改变而改变,如何将这种改变正确的传入到APP程序中?
解决方案:在我们编程时,编译输出的文件都有一种共同的文件格式:elf文件格式,elf文件格式有很多,其中有的elf文件中,携带了便于实现动态加载的相关信息,可以将重定位操作对代码的影响位置与影响方式以表格的形式表示,Windows,Linux也都是使用这种elf文件实现程序动态加载的。通过对这种特殊的elf文件进行解析,即可实现APP代码的相关数据的重定位。问题2:如何生成这样特殊的elf文件呢?
解决方案:本程序使用的MDK5的V6编译器,利用了armlink中的BPABI中basic_platform特性,实现了这种特殊的elf文件生成。问题3:主体程序是通过什么方式调用APP程序呢?
解决方案:主程序调用APP的程序有两种方法,第一种是直接通过APP的程序入口点进行调用,用于简单调用的情况,每个APP程序的程序入口点为APP程序中的dl_main函数,可以直接通过主体函数dl_get_entry获得APP程序入口点dl_main的函数指针,进而进行调用。第二种是通过函数名进行调用,使用dl_get_func,以函数名的方式在动态链接表中寻找对应的函数指针,进而进行调用。注意:当且仅当APP中定义的函数被DLL_EXPORT修饰时,此函数名才会出现在动态链接表中,才能被主题程序调用。问题4:APP程序如何调用主体程序的部分函数?
解决方案:在主体程序与APP程序间,约定一个固定地址的程序向量表,主体程序把相关函数指针填入到向量表中,APP程序通过查表获取主体程序的函数指针,进而进行调用。
程序源码相关文件介绍
主体程序包含头文件dl_lib.h,.c文件全部加入到工程中即可使用。APP程序编写可以参照附件中的模板工程(源码有点多,有需要在介绍)
ELF手册-中文版.pdf
其他说明
动态加载运行的程序性能与正常的有差别
在F1和F4上可能会有一点儿差别,动态加载会稍慢点,我这里只有H7的板子,没做测试。
在H7里,由于有Icahe,两个速度基本一样,没啥影响

APP动态加载测试程序

Host静态加载测试程序

实际测试效果,静态运行的函数与动态加载的函数运行时间基本一致
之前做国网产品的时候,国网提供的操作系统就是动态加载app,知道是rtt的lwp模块,但是一直没有弄清楚。请问动态加载bin文件可以吗?之前国网提供的操作系统就是通过ymodem下载bin,然后再动态启动
首先,我理解的Bin文件是纯粹的供单片机使用的二进制代码文件,不能直接直接动态加载bin文件,这直接是原理性的限制。RT-Thread也不能直接直接加载通常意义上的Bin文件。在动态加载时,程序代码的存储的位置是需要在运行时确定的,因此在动态加载时,需要更改机器码中所有与地址有关代码,这个操作需要链接器辅助支持(开启链接器的相关选项、编写相应的sct文件,示例的APP工程中有),链接器把与地址有关的代码位置与修改方式,以重定位表的形式附加在elf文件中,单纯的Bin文件中没有这个信息,因此也就不太可能实现。除非这个动态加载是存储在RAM的固定位置的,可那样的话也就不是真正意义上的动态加载了。
知道原理后,想法就可以特别多了啊,博主实现的是用MUC处理ELF文件得到可执行程序,你也可以使用上位机实现,甚至服务器实现也可以,最终都是得到可以运行的机器码,之前没有动态加载的功能是无法解决重定向的问题,博主这边文章实现重定向功能,只需要理解修改就可以了。
无论是MCU还是上位机或者服务器实现处理ELF文件得到可执行APP程序,都需要考虑APP程序固化问题吧,一旦MCU断电再上电还需要重新动态加载APP程序吧
ThreadX 的Module,是否可以参考下?
其实像这个动态加载的实现,参考ThreadX的moudle意义不大。当时实现陷入死胡同的时候,确实想着参考一下ThreadX的moudle,结果因为之前没用过ThreadX,没找到相关的实现在哪里。。。其实这种动态加载的实现都差不多,都是通过加载具有重定位信息的elf文件实现的,而且有很多的实现,都是需要依赖相应的工具链,比如RT-Thread的实现。我写的这个是根据elf文件结构实现的,好处就是比较通用,基本上只要是带有动态段的elf都支持,不过除了MDK5,其他工具链的就要自己研究研究怎么生成带有动态段的elf了
如果是单独加载函数,且函数只用到了入口参数和局部变量应该相当于跳转,比较容易;如果加载的代码需要用到其他函数或全局变量可能需要动态加载内容比较多
理解正确。其实重定位部分开销不算很大,而且只需要加载一次,后面在使用就和flash运行程序一致了
H7-TOOL的lua 语言就是这个特点。但是Lua 库需要的空间资源还是很大的。我的理解是用App 生成 elf文件,再通过一个上位机将 elf文件发送给 HOST,HOST解析这些函数。 是这样的吗?
差不多是这个意思。主机通过elf文件,把文件里程序的机器码回复出来,然后执行。与lua相比,空间资源要小很多很多,运行速度也是lua无法比拟的,另外不需要学习额外的编程语言,缺点就是比较依赖于工具链和芯片架构。
elf文件太大,能做成类似bin不
这个暂时没办法做成bin实现,因为bin文件里缺少用于重定位的辅助信息,不过如果将这个辅助信息保留,在添加到bin文件中,这样的话文件体积就会小很多很多。这个需要开发一个小工具实现这种操作,我没太接触过上位机开发,假期可以考虑实现一个这样的小工具
我后面又看了下链接器的命令行选项,通过命令行–nodebug –no-commment 可以把elf文件压缩的很小,基本上只保留了必要的信息。不知道是否满足你的要求
我们这之前用Keil的Overlay实现过不同Code占用相同RAM,楼主这个更彻底,即是ROPI也是RWPI,并且自己写了ELF Loader。学习一下,以后看要不要用在项目上。
threadx的module生成的bin文件体积小,文件的最前位置带了信息。像rtt的动态加载就是elf体积比较大,好处就是可以定好函数符号表方便调用
通过命令行配置可以让elf文件变小很多,在gitee提交的工程中修复了这个问题
在dynamic_loader那个仓库提交的
SVC_CM7_Keil.lib 请问 这个库是负责什么功能的,WZH大侠
SVC_CM7_IAR.a / SVC_CM7_GCC.a / SVC_CM7_Keil.lib: 16 bits mono/stereo and
multichannel input/output buffers, library runs on any STM32 microcontroller featuring a
core with Cortex®-M7 instruction set.
这个库是ST公司的一个智能音量控制的库,可以智能调节音频信号的增益,-80dB到36dB的范围
动态加载的工程是独立编译么?
被用来加载的elf文件与下载到单片机的工程是分开编译的,论坛里的app_elf_generate的工程用来生成被加载的elf文件,host_elf_loader则是用于解码加载elf文件的程序代码
有必要测试一下函数查找, 加载和释放的耗时.
这个不太好测,因为这个耗时是根据动态加载的elf不同而不同,主要的耗时操作如下。
dl_load_lib:读文件、分配内存空间、将elf文件的加载域复制到内存、地址重定位、分配函数字符串的空间。
其中地址重定位、分配函数字符串的空间与elf文件中的动态符号表数量有关,代码中和全局变量相关的代码越多,需要重定位的地方越多,导出的函数越多,句柄中的函数串越多。
dl_get_func:这个函数就是查表,根据字符串寻找到elf文件中的函数指针
dl_get_entry:这个函数返回句柄中的entry_addr,没有额外操作
dl_destroy_lib:释放掉加载elf文件的内存,释放掉字符串函数表的内存,与导出的函数数量正相关
在一般的使用中,这几个函数可以很快的执行完
楼主,请问一下:dl_load_shared_object函数中加载elf文件时,分配的是栈上的空间,那么函数退出后,这段空间不就没有了嘛,怎么还能后续再次执行动态库中的代码逻辑呢?

这是分配在堆上呀,函数退出依旧会保持的内存区
抱歉,从linux过来的,看到alloc函数就下意识的认为是在栈上开辟的空间。我追到底层看了下,虽然不太理解,但是看到malloc ralloc 和alloc都是差不多的汇编实现,感谢楼主的回复。
楼主你应该有发现用你这种方法(按你的工程进行编译)是有bug的.比如重定位时多个字符串的地址是同一个地址
源码和反汇编以及readelf


A:
这没问题,第一个Relocation为代码中引用全局变量的地址,这个肯定是不同的。
第二个是符号值,这个符号值其实是代表的这个全局变量在整个elf文件中的偏移地址,代码中多次引用同一个全局变量就会出现这种情况。
Q:
str = “test string\r\n”; 这句代码通过重定位后,str获取的地址是”hello world\r\n”的地址, 你认真看下,里面有三对movw movt需要重定位, offset 0006 000e 这一对是获取str的地址,其他两对是本来分别是要获取”hello world\r\n” 和 “test string\r\n” 的地址, 但是后面两对都是获取”hello world\r\n”字符串的地址.
A:
这汇编确实有点问题,你用的编译器版本是什么呀,我一样的代码,和你的反汇编完全不一样。
file:///C:/Users/wzh/Desktop/%E5%B1%8F%E5%B9%95%E6%88%AA%E5%9B%BE%202022-04-21%20093251.png
file:///C:/Users/wzh/Desktop/%E5%B1%8F%E5%B9%95%E6%88%AA%E5%9B%BE%202022-04-21%20093439.png
file:///C:/Users/wzh/Desktop/%E5%B1%8F%E5%B9%95%E6%88%AA%E5%9B%BE%202022-04-21%20093453.png
建议检查一下,重新编译生成一下试试



场景使用:
- 我们目前在MCU上跑dlmodule,可能更多是抱着学习,了解原理的心态,一般来说,动态模块会使用在RAM大于4MB的平台中。
- 动态模块可以对未来不可预知的一些功能的扩展
- 可以做到类似于安卓app,把一些特殊功能的应用交给第三方的模块独立完成
- 调试使用,比如调试某个具体功能时,如果每次都修改整个项目工程的源码,然后编译,下载,如果整体烧写flash效率比较低,此时就可以使用动态模块调试
一定要用keil编译吗? gcc不行?
程序分为两部分,一部分是用于加载程序的动态加载器,这部分可以用任何平台编译。
另一部分是被动态加载的程序,这部分使用Keil编译的,因为本文中的生成用于动态加载的程序利用了Keil的链接器的部分特性。如果gcc有这部分特性的话,当然可以用gcc编译,只不过需要自己研究一下相关的编译器与链接器手册。
其他:可以用GCC-ARM-NONE-EABI 编译器试一下,需要自己写.ld文件,.ld文件也可以借助STM32CUBE IDE 配置生成,然后再根据楼主.sct文件改改就好了
版主你好,你发的教程里动态加载的实现,使用RAM空间较小的MCU能实现吗,比如stm32l431 64kRAM。是不是app代码不能写的太大,因为程序是加载到RAM中运行的?
没错,是在ram中运行的。单个app的代码写的太大确实会装载不下,像这种情况可以把一个大的app拆成多个小的来加载。
使用GCC编译 dl_vector.c 会有stdin、stdout、strerr initializer element is not constant 的error,这个问题有人遇到过吗
A: 这几个变量和编译器有关,我这个只适用于arm clang编译器
楼主,您好。看你的文章大受启发,已经移植成功RTT的rt_err_t dlmodule_load_relocated_object(struct rt_dlmodule* module, void *module_ptr)
我请教一个问题,像这种Relocation type for arm的符号如何找到对应的汇编指令以及解析方式,我看您实现了R_ARM_THM_MOVW_ABS_NC 以及R_ARM_THM_MOVT_ABS,有相关资料去了解吗
谢谢~期待你的回复
这个我当时是在arm官网关于动态加载的文章中找到的,那篇文章链接现在失效了,可以在官网里再找找看。原文链接如下:https://developer.arm.com/documentation/ihi0044/h/?lang=en#dynamic-linking
我已经在mdk环境和gcc环境测试都OK了,不过在你的工程上我只保留了uart、led、sd 这三个外设,你提供的资料帮助很大,非常感谢
函数表这些我都剪掉了,测试的时候自定义简单的就好了,后面有需要在慢慢添加
楼主,现在我工程里面可以动态调用函数了,不过我是裸机环境,子程序中调用的printf、clock等函数,现有的实现方式不行,按您的做法现在是会卡死,裸机环境下的实现您有研究过吗?由于不能使用SVC指令,我的理解应该要自定义管理中断服务程序、中断向量表等
我想的一种简单点的方式是主程序挂载回调函数的方式,提供给子程序调用,实现体还是在主程序中,我还未验证是否可行,即使可行,子程序代码可移植性没那么好
有什么建议提供给我参考吗,感谢
A:
我帖子里的工程好像有点问题,最好还是用gitee上的工程,另外我能想到的比较简单的方法就是约定一个固定的地址,把app要调用的函数指针以数组的形式存在这个地址里,app通过固定地址加偏移量,获取函数指针进行访问。
能否使用全局的参数?比如主程序的一些结构体成员
可以,可以将全局变量用指针传递进去
请问,这个动态加载,可以支持RTOS吗? 例如使用freeRTOS?
支持,我用的RTX5
Q:非常感谢!我要深入的研究一下!现在不适用OS,简直已经不能用了。看来这个也可以移动到ThreadX下了。Thread-X下的MODULE主要是不能作为库使用。 我主要是需要动态加载很多的库!
Q:
这里还是有个迷惑的地方:
操作系统每个任务都是有自己的栈空间的,用来进行局部变量。
动态加载的函数,使用哪里的栈呢? 因为OS任务切换的时候,都是维护自己的任务栈。 这里有点迷糊!
A:
arm单片机入栈出栈都是使用专用的PUSH,POP指令的,具体PUSH,POP的栈空间地址,是由MSP与PSP指针决定的。换言之,哪块调用了动态加载的代码,就使用哪里的栈空间。
谢谢分享,你的elf loader跟这个文章是类似的吗
https://ourembeddeds.github.io/blog/2020/08/16/elf-loader/
对,我的实现方法和这篇文章大体思路是一样的,但在具体操作上略有不同。我没做符号表的支持,也就是在编译时不链接一些函数,而是在动态加载时在链接。因为MDK5的编译器在编译base_platform属性的elf文件时,在编译期时就需要确定所有函数的定义,要不然无法链接。同时不使用这种符号表导入的方式可以大幅减少加载的的过程。
ELF Load: Dynamic load and execute for your mcu.
But wait! This is not totally the old-fashionist experience… My binaries must be embedded in the firmware in order to work! You also shouldn’t expect to be able to listen to your old 5’’ 1/4 drive (or better, your dataset) but the fresh experience of binary loaded is lost for ever and never… or not?
Loading binaries, the simplest way
In an old PC, when you type a command, the operating system searchs a file with the command name and extension COM (or EXE in newer versions) and tries to load it… At this moment, several things happen:
- The system calculates memory usage of the executable and reserves this amount of memory in the system
- The OS reads the file and copies the pertinent areas in the reserved memory.
- Depending on architecture, some adjustments to loaded data may be needed. In the case of 8086 and
*.comfiles, the architecture of the memory management unit enables load without any adjustments in this phase. - An execution environment is created (reserving memory if required) and configures some registers of the processor to point to this environment before the next phase
- Finally, the OS jumps to the entry point of binary and delegates the execution to the recently loaded code
As mentioned in the point 3, normally in a PC processor the architecture enables execution with minimun or unexisting binary modifications (segmentation in 8086 and MMU in modern x86 systems).
You can see next, the 8086 memory layout at COM executable load:

In this example, the binary is limited to 64K of memory and the processor reserves one of the segments for the program usage (in the execution, the program can load more code or request more memory to OS, but the binary is limited to one 64K segment). In modern systems with a memory management unit (MMU), you can map any virtual direction to any real direction (well, not exactly… in 4K blocks of granularity, but you do understand, right?) and can select the memory layout of your executable freely.
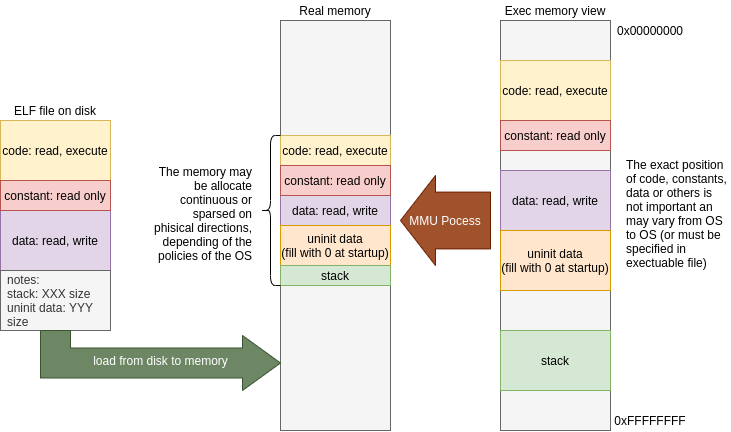
Usually, the process to load executable in MMU systems is more complex, involves copy of a portion of the file dynamically at request using a virtual memory trick called page-fault. In short, you only need to configure the memory of your process with required pages and mark as no-present this pages; at the moment is necessary to access these pages, the hardware triggers an interrupt thath is caught by the OS who proceeds to load these pages for you.. cool don’t you think?.
But when you try to replicate this behavior in your embedded system… the magic is gone and you will quickly see the problem: You need to use fixed address for your binary load:
This schema works more or less properly for a single executable, but if you need nested executable load or multithread load, this approach is quickly wasted.
In many architectures (highlighting ARM, MIPS and RISC-V) the jumps normally refer to the current program counter (PC) to jump. In this architectures, the code is easy loadable in any position of memory (respecting some rules of aligns) but the data is more complex because it needs one or two indirections to refer a proper memory area independently of the load position.
Fixing the world one word at time
If your processor lacks MMU, to load programs at arbitrary addresses, you can look for several approaches:
- Make the code suitable to detect the current address and adjust their references in accordance to it: This is called “position independent code” or PIC (similar approach with very subtle differences is called “position independent executable” or PIE) and implies one or two levels of indirection in any code. But don’t celebrate yet, the PIC code has various challenges to solve:
- Jump of code independent of position: This normally is made using special processor features like PC relative jumps. This is easy when the compiler knows the relative position of code in compile time, but becomes difficult when the address of the code is dinamically calculated, like in jump tables.
- Access data in arbitrary loadable position: Normally, the PIC code uses indirect access through a relocation table called global offset table (GOT) modified by the loader before code startup.
- Mix of previous points: Normally, when your code jumps to a calculated position, you need a GOT entry reserved for this calculus and need to adjust this entry like other data access. Due to optimization, the compiler may prefer other approach, using an stub of code adjustable at startup for perform this dynamic jump. This technique is called procedure linkage table and consists in a little stub of code that performs a call to undefined pointer (normally an error function) and the loader adjusts this code in load time to point to the correct code block. This approach enables you to share code in libraries, although it requires a little more of work.
- Leave any memory reference as undefined and mark in a table the needed to modify this portion of code in order for the program to work.
The first approach needs less work in the loader area but the performance at runtime is worse than the fixed memory address code. In contrast, the second approach needs more loader work but the performance of the code is nearly the same as the fixed address code…
In the end, the PIC code is the only suitable way to share code across multiple libraries for single binaries. For example, with the PIC code you can have a one library for string formatting (aka printf) and share the code with many programs. Additionally, the PIC code can reside in flash without any modifications, only a PLT and GOT is required in RAM, and change from program to program (this require OS help on context switch).
Global offset table schema
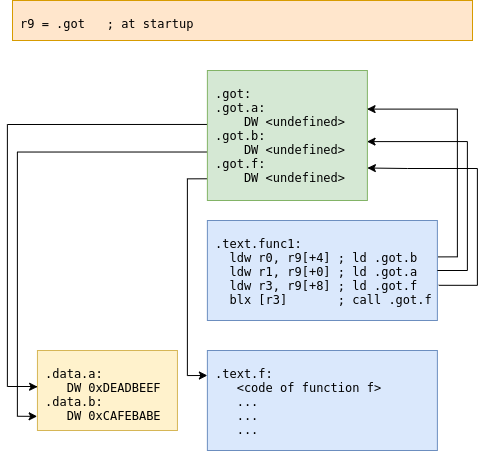
Relocation schema
1 | // extern int f1(int, int, char); |
Put ya guns on!
Our preferred approach in embedded systems is to load the code and relocate individual references instead of GOT usage due to the performance degradation of adding two indirections (one for GOT pointer and one for GOT entry) in every memory access.
In MMU systems, the ELF load process is really straightforward:
- Map the file from disk to memory (with help from MMU and OS swap service) and resolve memory map to satisfy the ELF layout.
- Scan a relocation table and resolve undefined symbols (normally from dynamic libraries in the system).
- Make a process environment and adjust the process register to point to it (normally an in-memory structure representing the process state).
- Let the OS load the new processor state with the correct environment. Normally, this is limited to putting the process state in a ready queue in the OS structures and letting the scheduler do the switch process when available.
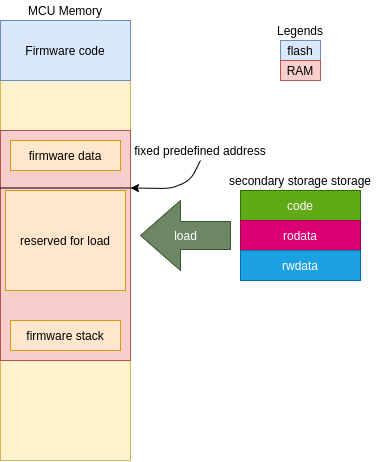
Without MMU, the process require some precautions:
- You cannot load the entire ELF from secondary storage because this action consumes more memory than expected (the ELF may contains debugging sections, some unneeded information like symbol tables and other non required data at runtime).
- The memory is non-virtualized, all process share the same memory space and can potentially access (in a harmful way) the memory from other process… You need to take precautions, some MCU have a protection memory system (like MPU on ARM or PMP on RISC-V) to mitigate this issue.
- You need to reserve only loadable sections like
.text,.data,.rodata,.bss, and.stack, other sections are only used at the load time like relocation symbols and elf header. - You need to travel trough all symbols and relocate every entry in the binary… this may take some time but the execution time has little impact compared with the PIC code.
You can see our implementation of the load-relocate schema in this link.
Due to the simple nature of the loader, it cannot handle all type of relocations and sections. Ideally, you can extend the code to cover your necessities, but the actual implementation works fine with some precautions at the moment of guest binary compilation:
- You cannot use “COMMON” sections, all of non initialized data must be in BSS. The gcc flag to force this is
-fno-common. - You need to link the final ELF as a relocatable executable. This prevents the linker from resolving undefined symbols, instead it embeds the information needed to resolve the symbols in the binary. The gcc or ld flag to force this linking behavior is
-r. - You need to force the compiler to produce only “word relocation” types. This is the simplest relocation form and is easier to handle in load time. In ARM architecture, this forces all relocations to be of type
R_ARM_ABS32. To enable this, gcc for ARM provides the flag:-mlong-call. In old compilers this is not strictly true and the flag will not produce correct results, many relocations will be of typeR_ARM_THB_CALLorR_ARM_THB_JMP. Don’t panic, the actual loader can handle this type of relocations, but the load phase will be sensibly slower due to major processing work. - By default, all compilers provide a startup library that is executed before main, and initializes some data and code for you, but this is undesirable in this situation. You need to disable the inclusion of these codes and provide a self written version to
_startor other function of your election. This behavior can be enabled in gcc using the-nostartfilesflag.
Additionally, you can provide a linker script with your preferred memory layout, but the suggested minimum linker script layout looks like this:
1 | ENTRY(_start) |
This places all sections in contiguous memory. If your architecture requires some align, you need to add “. = ALIGN(n);” statements between sections.
At this point, the loader API is really simple:
Initialize it.
You need to define an environment variable for the new binary with:
1 | typedef struct { |
This contain a reference to an array of resolvable symbols and the number of the elements inside the array. The entries of this array contain the name and the pointer to be resolved:
1 | typedef struct { |
Additionally, you need to create an object of type loader_env_t and set the symbol table inside this struct.
1 | ELFExec_t *exec; |
In the next phase, you need to call load_elf with the PATH of the binary, the environment and a reference to the pointer of ELFExec_t:
1 | load_elf("/flash/bin/test1.elf", loader_env, &exec); |
If the operation ends successfully, the return status is 0. In case of an error, it will return negative number indicating the specific error.
In this point, you have the binary loaded and allocated in the memory, and you can jump into start entry point or request the address of specific symbols:
In the first case, you need to call the function like this:
1 | int ret = jumpTo(exec); |
If the program ends successfully, the function returns 0, otherwise it will return a negative number depending to the error.
If you need to request an specific function pointer you can use
1 | void *symbolPtr = get_func("myFunction", exec); |
This returns a pointer to the function start or NULL if the object is not found.
If you need an arbitrary pointer to other symbol (variable, constant or whatever) you can use:
1 | void *symbolPtr = get_obj("myVar", exec); |
After all, you can free all allocated memory for the binary and the metadata of the ELF file with:
1 | unload_elf(exec); |
System interface
In order to be flexible in the implementation, the library leaves undefined some API of low level access for port to any system.
The low level layer need the following macros defined:
LOADER_USER_DATA: Structure or datatype to contain the platform dependent data for file access. For example, this needs at least, a file object (integer file descriptor, FILE* struct, or whatever) and an environment pointer toELFEnv_t.LOADER_OPEN_FOR_RD(userdata, path): open file in path and modify userdata in order to save the file descriptor, or file pointer.LOADER_FD_VALID(userdata): Check if the opened file data is a valid file and can be read from.LOADER_READ(userdata, buffer, size): Readsizebytes from file descriptor inuserdataand put it inbufferarray.LOADER_WRITE(userdata, buffer, size): Writesizebytes to file descriptor inuserdatafrombufferpointer. This macro is not used internally, it is only defined in symmetry with the macro above.LOADER_CLOSE(userdata): Close the file descriptor inuserdata.LOADER_SEEK_FROM_START(userdata, off): Move read pointeroffbytes from the start of file pointed by descriptor inuserdata.LOADER_TELL(userdata): Return current position of file descriptor inuserdata.LOADER_ALIGN_ALLOC(size, align, perm): Returnsizebytes aligned asalignbytes withpermpermission access. If you do not provides differentiate access of memory region, the returned region can be write, read and execute. By default, the macro call a functionvoid *do_alloc(size_t size, size_t align, ELFSecPerm_t perm);.LOADER_FREE(ptr): Deallocate memory from pointerptrLOADER_STREQ(s1, s2): Compare two strings s1, and s2. The result of equal strings must be!= 0and when the strings differ, the result of this macro must be0. The simplest implementation is:(strcmp((s1), (s2)) == 0)LOADER_JUMP_TO(entry): Perform a jump to application entry point.entryis the address of the first instruction of the code. You can simply cast the value to a function pointer with selected fingerprint or do a more complex operation like environment creation, start a new RTOS thread or whatever is required for your architecture.DBG(...): Print (in printf like format) debug messages. Can be empty if you do not need debug messages.ERR(...): Print (in printf like format) error messages. Can be empty if you do not need error messages.MSG(msg): Print (in printf like format) information messages. Can be empty if you do not need information messages.#define LOADER_GETUNDEFSYMADDR(userdata, name): Resolve symbol namenameand return its address. The most simple way to do this is to perform a search in specific structure underuserdatawith a symbol table. If the process fail, the data returned must be0xffffffffAKA((uint32_t) -1)
The golden implementation uses ARM semihosting IO for file access, but you can port this to any API like fatfs or similar.
contiki里面也实现了动态加载
https://github.com/contiki-os/contiki/blob/master/core/loader/elfloader.c
https://github.com/contiki-os/contiki/wiki/The-dynamic-loader
相关链接(侵删)
欢迎到公众号来唠嗑:

 微信
微信 支付宝
支付宝
